Prompt Is Not Runtime
LLMs shouldn't replay workflows. They should edit intent.

One afternoon in mid-April, product pinged us: the ad-launching agent had been spinning for twenty-plus minutes without success, spawning a pile of non-compliant campaigns along the way. Also, could I please add support for a finance app right now?
I work on launch infrastructure. The parameter support was easy enough. But when I looked at how the bot team had wired ad-launching into the agent, I found something else:
a 600-line markdown file.
Inside:
Parameter combinations for each objective
Per-error-code recovery branches
Cross-field constraints
Retry rules
Fallback paths
Meta ad launching is genuinely complex. The problem was never just filling in values—it’s field combinations, cross-field constraints, default inheritance, error recovery. Everything that should have lived in runtime had migrated, one rule at a time, into markdown.
Each new rule surfaced a new error shape on the next run. Each new branch made the prompt longer. The next run hit another Meta exception this file had never seen.
That afternoon a sentence surfaced in my head:
I don’t want to be a markdown-driven programmer.
Later I realized: the real problem wasn’t prompt length.
It was that:
We weren’t writing prompts. We were quietly rewriting a runtime.
Hidden Runtime
The 600-line prompt wasn’t mine. The bot team had hooked into an early version of my system’s API.
That API was designed for deterministic callers:
Microservices
Web UIs
Fixed workflows
Stable payloads
A caller is assumed to know:
The flow ordering
What each field means
Which values should inherit
Which should override
When to retry
An agent caller is not that thing. So execution semantics—implicitly carried by the system, the frontend state machine, the workflow engine—started leaking into the prompt:
What step 1 does
What step 2 does
Which errors trigger retry
Which fields can’t coexist
Which configs inherit by default
Things that should have lived in runtime got translated back into natural language and re-fed to a model that’s already doing semantic interpretation.
I’ve started calling this anti-pattern markdown parroting. Engineers write business workflows as markdown teaching material; the LLM replays the workflow pattern. Every new production error gets another paragraph: “this is how to recite it this time.”
The LLM is forced to re-execute the backend’s implicit logic in its own token stream. It isn’t a caller anymore. It’s a parrot being drilled by markdown.
Two Problems, Conflated
I initially thought this was one problem. Later I realized: the 600-line prompt had two completely different things compressed into the same natural-language patch.
The first: nobody holds the flow anymore.
A web UI used to hold execution state for the system:
Authenticate first
Then pick an objective
Then configure pixel
Then configure audience
That state machine and business-flow control disappeared in the bot form factor. So you start writing in the prompt: “step 1 does this, step 2 does this.”
The second: the payload is genuinely complex.
A Meta campaign has hundreds of parameters. Asking the LLM to assemble the correct payload in one shot is structurally unstable.
Both degenerated into the same fix: keep adding teaching material to the prompt. Every paragraph patches one error; every patch introduces the next prompt drift.
Continuing to edit the prompt just sinks you deeper into parroting.
Progressive Intent
That night, talking it through with ChatGPT, I realized we’d been framing this wrong—as a prompt-engineering problem. Split the schema finer, add more examples, write the prompt more precisely. But the entry question itself was wrong.
Not:
“How do we get the AI to write a correct big JSON in one shot?”
But:
“Why is the AI writing a big JSON in one shot at all?”
The full payload is an execution shape inherited from the RPC / HTTP API era. A deterministic caller already knows what it wants before issuing the request, so submitting a complete payload in one shot minimizes round-trips.
An LLM is not that kind of caller. Its intent doesn’t exist fully-formed in advance—it converges through reasoning, feedback, constraints, and user clarification.
What it’s actually good at isn’t generating complete runtime state in one shot. It’s converging on semantic intent under structured feedback.
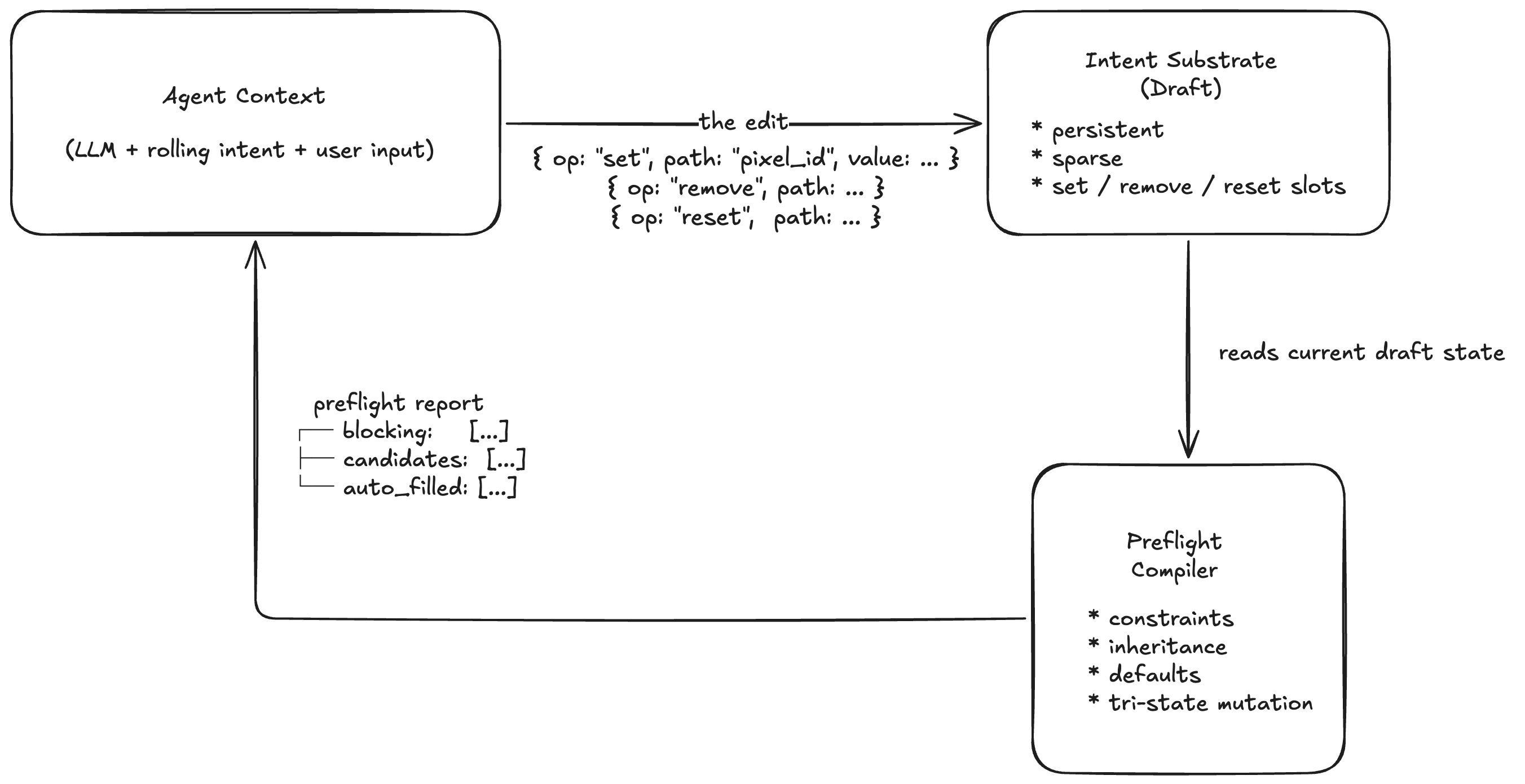
I started calling this execution model progressive intent. Instead of submitting a final payload in one shot, the LLM edits a persistent intent substrate incrementally:
Express coarse intent first
Fill in details
Leave uncertain parts blank
Let the system surface gaps, conflicts, and candidate values
Complex business writes shift from “generate full payload in one shot” to “incrementally edit a persistent intent substrate.”
I call this substrate the draft. After each edit, the system returns something that isn’t an error message—it’s an intent-gap report:
{
"blocking": [{ "path": "budget.daily_amount", "reason": "required" }],
"candidates": [{ "path": "objective.optimization_goal",
"options": ["APP_INSTALLS", "OFFSITE_CONVERSIONS"] }],
"auto_filled": [{ "path": "timezone", "value": "Asia/Shanghai" }]
}
What’s still missing, what has candidate values to pick from, what the system has auto-populated from bindings. The LLM receives the kind of signal it’s actually good at—structured-feedback-driven semantic convergence, not guessing the next move from an error message. I call this feedback preflight.
The 600-line prompt was, fundamentally, asking the LLM to reproduce the entire backend runtime inside its own context window. Progressive intent inverts this: let the model do only what it’s good at; return deterministic execution semantics to the system.
Not every operation deserves this substrate. Pausing a campaign, reading status—one-shot, low-side-effect operations. A direct tool call is enough.
The operations that actually want progressive intent are the multi-entity, relational, side-effectful, convergence-requiring writes. Ad launching is one of them. There are others.
Semantic Collapse
But progressive intent doesn’t hold up because it’s “more elegant.”
It holds up because production exposed, fast, that the old execution semantics couldn’t carry what an agent caller was actually trying to say.
Meta subcode 1815229, Promoted Object Contains Unsupported Fields.
An APP_PROMOTION campaign goes to publish; the backend auto-attaches a default pixel. The LLM didn’t make a mistake—it knew APP_PROMOTION shouldn’t carry a pixel and omitted promoted_object.pixel_id from its patch. But the compiler saw a missing key, applied “user didn’t fill it, inherit the default,” and silently put the project’s default pixel back. Meta rejects.
The LLM retried in the dialog. Each time, the default slipped back in. Nothing worked.
Later, in a design doc, I wrote one line:
missingis being used to meaninherit;missingis being misused to meanremove.
That was the moment I saw it: the problem wasn’t prompt length anymore—it was that the execution boundary had collapsed.
A backend designed for deterministic callers, meeting a probabilistic semantic actor, needed a semantic granularity one level deeper than “is the field present or not.”
What the LLM wanted to say was: “I explicitly don’t want a pixel.” What the system could hear was: “the user has no opinion.”
Neither side was wrong. What was wrong was that there was no semantic mutation boundary between them.
The system had to grow set / remove / reset—explicit mutation semantics:
{ "path": "pixel_id", "op": "set", "value": "12345" } // I want this value
{ "path": "pixel_id", "op": "remove" } // explicitly do not
{ "path": "pixel_id", "op": "reset" } // withdraw, fall back to default
Three different semantics, all collapsing into the same missing key in a set-only wire form—that’s what the collapse actually is. Not “tri-state IR is sophisticated.” A set-only business model couldn’t carry what the agent was trying to say.
Prompt Is Not Runtime
That 600-line markdown file? We eventually deleted it.
Once complex business writes were re-modeled as incremental edits to a persistent intent substrate, the LLM stopped hallucinating full runtime state in one shot. It started expressing only what it was actually certain of:
“I want this campaign.” “This field, definitely not.” “Inherit the default here.” “Withdraw the last choice.”
The system reclaimed constraint, validation, reconciliation, and state alignment.
The LLM stopped replaying workflows. It started purely editing intent.
That was when I finally saw what’s absurd about the current state of agent infrastructure: the endpoint of prompt engineering is not a longer, more precise prompt.
It’s admitting that what we called “prompt engineering” was ultimately an attempt to push execution semantics back into natural language.